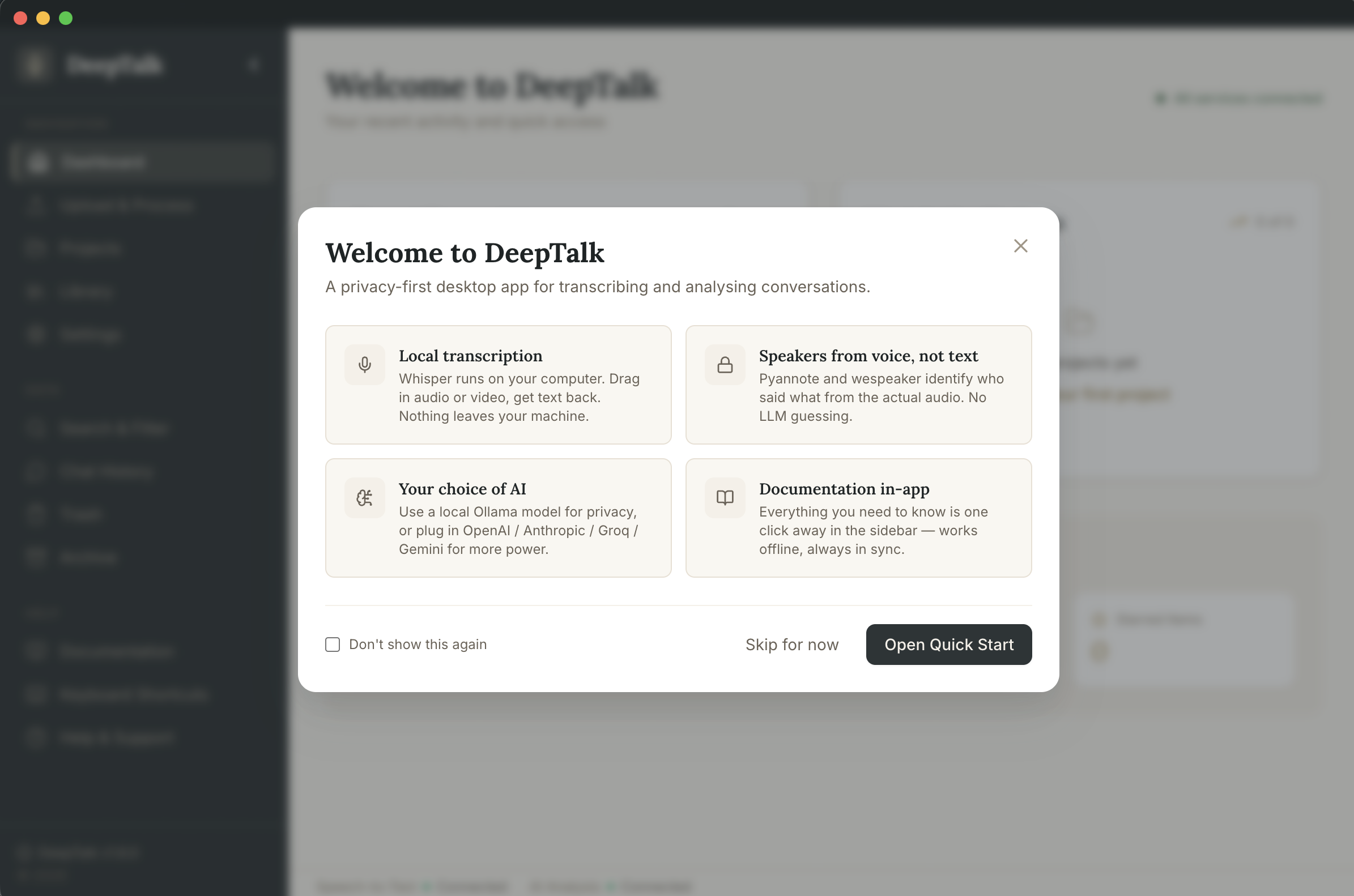
Deep Talk
Transcribe, diarise, and analyse conversations on your own machine — then let the AI surface the insights.
What it does
Local transcription
Built-in Whisper via @huggingface/transformers runs fully on your machine — no external server required.
Speaker diarisation
pyannote-segmentation-3.0 + wespeaker gives real audio-level "who said what" instead of LLM guessing from text.
Audio & video support
MP3, WAV, MP4, AVI, MOV, M4A, WebM, OGG and more. FFmpeg is bundled so it just works.
Bring your own AI
Analyse with local Ollama, or Anthropic, OpenAI, Groq, Gemini, OpenRouter, or a custom endpoint — your call.
Privacy-first
Transcription and diarisation stay on your device. Nothing leaves the machine unless you choose a cloud model.
In-app docs
Full documentation ships with the binary and renders in the app's theme — no internet required.
How it works
Drop in a recording
Open any supported audio or video file — interviews, lectures, meetings, field recordings.
Transcribe locally
Whisper runs on your machine to produce an accurate transcript with timestamps.
Identify speakers
Diarisation separates voices from the audio itself, so each line is attributed correctly.
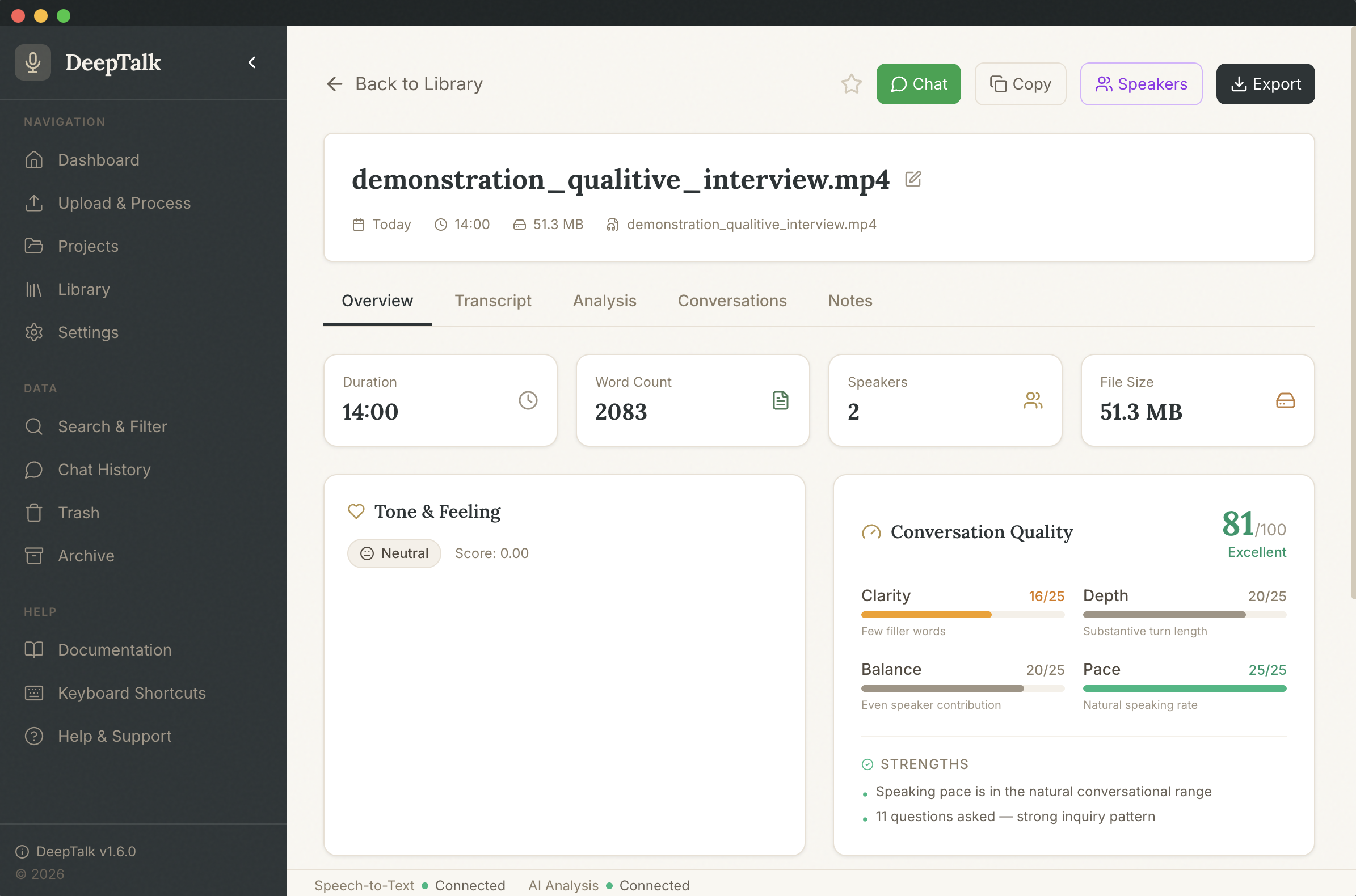
Analyse & explore
Ask the AI for summaries, themes, quotes, or custom analyses — locally or via your preferred provider.